
期末复习——软件安全
软件安全复习
综述(不考)
缓冲区溢出基础
###缓冲区溢出原理
缓冲区溢出 -> 当计算机向缓冲区内填充 数据位数超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
一般发生在写入内存的数据超过了分配给缓冲区的大小
进程内存空间分区
按照内存地址从高 (0xffffffff)到低 (0x00000000)的顺序排列,可分为5大分区:栈区 -> 堆区 -> 数据区 -> 代码区。
系统栈的工作原理—内存的不同用途
| 分区 | 功能 |
|---|---|
| 代码区 | 存储被装入执行的二进制机器代码,处理器会到这个区域取指并执行 |
| 数据区 | 存储全局变量等 |
| 堆区 | 进程可以在堆区动态地请求一定大小的内存,并在用完后归还给堆区。特点:动态分配与回收 |
| 栈区 | 用于动态地存储函数之间的调用关系,保证被调用函数在返回时回复到父函数中继续执行 |
函数栈帧、函数调用原理
函数栈帧,一般包含以下几类重要信息
| 信息 | 功能 |
|---|---|
| 局部变量 | 为局部变量开辟空间 |
| 栈帧状态值 | 保存前栈帧的顶部和底部,用于在本帧被弹出后恢复出上一个栈帧 |
| 函数返回地址 | 保存当前函数调用前的断点信息,以便函数返回时能恢复到被调用前代码区继续执行 |
函数调用原理
- 参数入栈:将参数从右向左一次压入系统栈
- 返回地址入栈:将当前代码区调用指令的下一跳指令地址压入栈中,供函数返回时继续执行
- 代码区跳转:处理区从当前代码区跳转到被调用函数的入口处
- 栈帧调整:保存当前栈帧状态 -> 将当前栈帧切换到新栈帧中 -> 给新栈帧分配空间
字符串安全
常见的字符串操作错误
无界字符串复制、空结尾错误、截断、差一错误、数组写入越界、不恰当的数据处理
不安全字符串API
strcpy() 、strcat() 执行的都是无边界复制操作,容易出现问题。
gets() sprintf()容易出现字符串截断等问题
字符串问题导致的安全漏洞
| 信息 | 功能 |
|---|---|
| 缓冲区溢出 | 向为某特定数据结构分配的内存空间边界之外写入数据 |
| 程序栈 | 栈可以通过存储特定内容来追踪程序的执行和状态。 |
| 弧注入 | 将控制转移到已经存在于程序内存空间中的代码中 |
| 代码注入 | 攻击者创建一个恶意参数(被合法接受,导致漏洞代码路径执行,在执行前不能导致程序非正常终止),当函数返回时,控制被转移到恶意代码 |
缓解与防范措施
缓解措施:
预防缓冲区溢出
侦测缓冲区溢出并安全回复,使得漏洞利用的企图无法得逞
防范策略:
- 静态分配空间
- 输入验证
- 采用更不容易出错的方式来复制和链接(
strlcpy() 、strlcat()) - 使用更少出错的C标准函数
- 动态分配缓冲区
- 采用
SafeStr - 使用
XXL库来执行错误处理 - 做好字符串管理
- 使用一个不透明的数据类型管理字符串
- 定义字符黑名单,用下划线或其他无害的字符来取代危险的字 符串输入
- 定义字符白名单
软件漏洞基础
软件漏洞的概念
把能够引起软件做一些“超出设计范围的事情”的bug(软件逻辑缺陷)称为漏洞
软件漏洞的危害
- 无法正常使用
- 引发恶性事件
- 关键数据丢失
- 秘密信息泄露
- 被安装木马病毒
软件漏洞出现的原因
- 小作坊式的软件开发
- 赶进度带来的弊端
- 被轻视对的软件安全测试
- 淡薄的安全思想
- 不完善的安全维护
漏洞利用技术
Shellcode与exploit的概念
shellcode : 缓冲区溢出攻击中 植入进程的代码
exploit: 代码植入的过程 (漏洞利用)
栈帧移位与 jmp esp
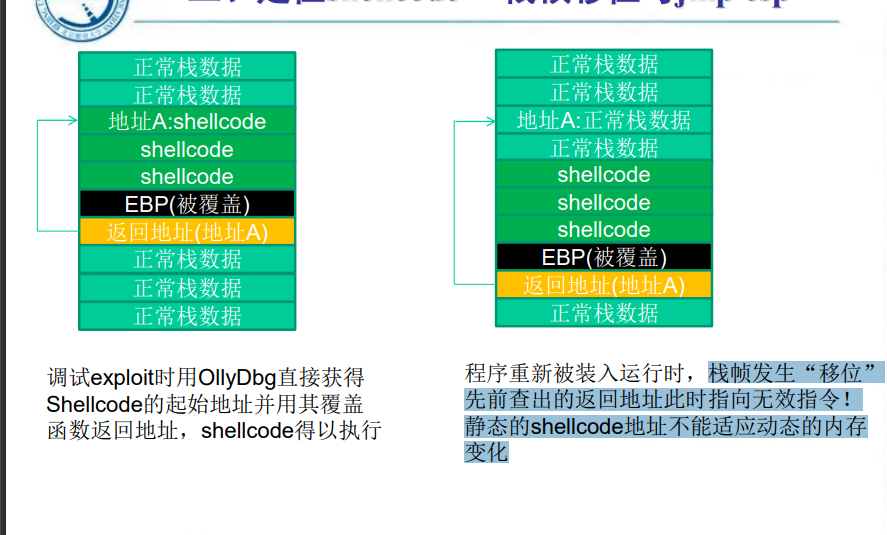
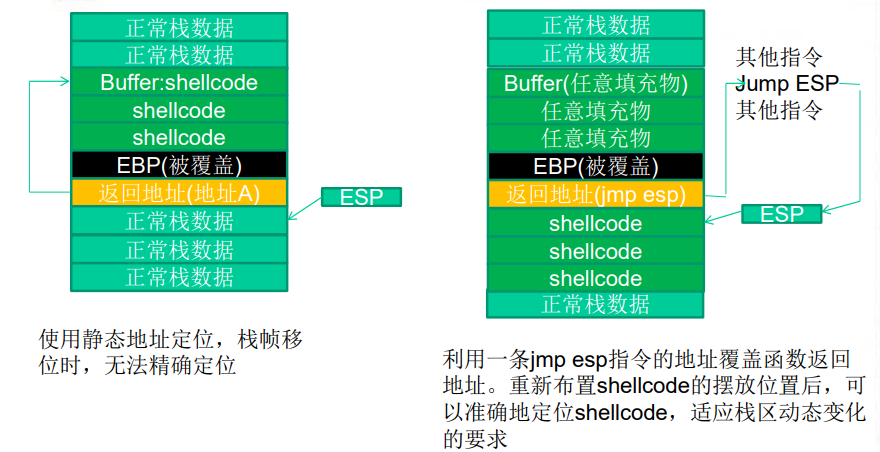
缓冲区的组成
- 填充物:可以是任何值 ,NOP指令用 0x90 填充
- 淹没返回地址的数据:可以是跳转指令的地址,shellcode 的起始地址 或者近似的 shellcode 地址
- shellcode:可执行的机器代码
漏洞挖掘与模糊测试
fuzz测试的概念与主要目标
概念:利用不断向目标程序发送或者传递不同格式的数据来测试目标程序的反应的自动化检测,然后监视检查其最后的结果,如果符合某种情况就认为程序可能存在某种漏洞或者问题。
主要目标:Fuzz的主要目的是”崩溃 crash”,”中断break”,”销毁destroy”
文件格式fuzz测试的主要步骤
- 以一个正常的文件模版作为基础,按照一定规则产生一批畸形文件
- 将畸形文件逐一送入软件进行解析,并监视软件是否抛出异常
- 记录软件产生的错误信息,如寄存器状态、栈状态
- 用日志或其他UI形式向测试人员展示异常信息,以进一步鉴定这些错误是否能被利用
Smart fuzz的主要特征
- 面向逻辑:测试目标为程序逻辑
- 面向数据类型:根据生成的不同数据类型生成不同规则的畸形文件
- 基于样本
指针安全
基本概念
指针安全是通过修改指针值来利用程序漏洞方法的统称。
修改指令指针
IC(Instruction Counter)
- 存储了将要执行的下一跳指令地址
- IC 不能被直接访问
- IC在顺序执行代码时递增,也可以由控制转移命令间接修改 (
jmpConditional jumpcallret)
内存任意写技术
控制 IC 使得攻击者可以选择要执行的代码
- 攻击者能够任意写的话,很容易
- 间接的函数引用与无法在编译期间决定的函数调用可以被利用,IC的下一个值,存储在内存中,其可以被改变 ,从而使程序的控制权转移到任意代码。
虚函数
- 使用关键字 virtual进行修饰,则被称为虚函数。
- 虚函数的入口地址被统一保存在虚表中
- 对象在使用虚函数时,先通过虚表指针找到虚表, 然后从虚表中取出最终的函数入口地址进行调用
- 虚表指针保存在对象的内存空间中,紧接着虚表 指针的是其他成员变量
- 虚函数只有通过对象指针的引用才能显示出其动 态调用的特性
SEH
- S.E.H -> 异常处理结构体 ,Windows异常处理机制所采用的重要数据结构。 每个S.E.H包含两个DWORD指针:S.E.H链表指针 和异常处理函数句柄,共8个字节
- SEH结构体存放在系统栈中
- 当线程初始化时,会自动向栈中安装一个S.E.H, 作为线程默认的异常处理。
- 如果程序源代码中使用了
__try{}__except{}或者 Assert宏等异常处理机制,编译器将最终通过向当前 函数栈帧中安装一个S.E.H来实现异常处理。 - 栈中一般会同时存在多个S.E.H
- 栈中的多个S.E.H通过链表指针在栈内由栈顶向栈底串成单向链表,位于链表最顶端的S.E.H通过 T.E.B(线程环境块)0字节偏移处的指针标识。
- 异常发生时,操作系统会中断程序,并首先从 T.E.B的0字节偏移处取出距离栈顶最近的S.E.H,使 用异常处理函数句柄所指向的代码来处理异常
- 当离“事故现场”最近的异常处理函数运行失败时, 将顺着S.E.H链表依次尝试其他的异常处理函数。
- 如果程序安装的所有异常处理函数都不能处理,系 统将采用默认的异常处理函数。通常,这个函数会弹 出一个对话框,然后强制关闭程序
Windows内存安全机制:GS编译、DEP、Heap cookie、Safe Unlink、ASLR
GS编译:为每个函数调用增加了一些额 外的数据和操作,用以检测栈中的溢出。
在函数返回地址前 首先检测Security Cookie是否被覆盖,从而把针 对操作系统的栈溢出变得非常困难。
DEP(Data Execution Protection 数据执行保护):将数据部分标识为不可执行,阻止了栈、 堆和数据节中攻击代码的执行。
Heap cookie:与栈中的security cookie类似, 微软在堆中也引入了cookie,用于检测堆溢出的 发生。Cookie被布置在堆首部分原堆块的 segment table 的位置,占一个字节。
Safe Unlink:在卸载free list的堆块 时,对节点进行验证,保证节点有效,不是伪造的。
格式化输出
格式化输出函数原理
格式化输出函数参数由一个格式字符串和可变数目的参数构成
➔格式化字符串提供了一组可以由格式化输出函数解释执行的指令
➔用户可以通过控制格式字符串的内容来控制格式化输出函数的执行
典型的格式化输出函数和格式化符
格式化输出函数:vfprintf fprintf vprintf printf vsprintf sprintf vsnprintf snprintf syslog()
格式化符:%x %s %d %ld %f
格式化输出函数可能导致的安全问题
- 缓冲区溢出
- 可拓展的缓冲区
- 使程序崩溃
- 查看栈内容
- 查看内存内容
- 覆写内存
可扩展的缓冲区
用户输入可被操纵用于覆写返回地址,也就是拿恶意 格 式 字 符 串 参 数 中 提 供 的 利 用 代 码 的 地 址去覆盖该地址,在当前函数退出时,控制权将以与栈粉碎攻击相同的 方式转移给利用代码。
使程序崩溃
在Windows中读取一个未映射的地址将会导致系统 的一般保护错误并导致程序非正常终止
覆写内存
- 通过使用转换指示符%n ,攻击者可以向指定地址中 写入一个整数值。
- 攻击者用某些shellcode的地址来覆写地址。
- 如果攻击者能够控制格式字符串,那么他就能通过使用具有具 体的宽度或精度的转换规范来控制写入的字符个数。
- 可以按如下方式 写一个任意的地址: 1. 写入4个字节 2. 递增该地址 3. 写入另外4个字节
缓解与防范措施
- 限制字节写入:严格控制写入的字节数,防止缓冲区溢出(通过限制转换符或者使用更安全版本的格式化输出库函数)
- 进行严格的程序测试 ,使用
-Wformat等编译选项 - 词法分析,
pscan - 静态污点分析
Shankar - 调整变参函数的实现
- 实现 安全的变参函数
- 使用
FormatGuard通过插入代码实现动态检测。拒绝参数个数与转换规范所指定个数不匹配的格式化输出函数调用 - 使用
Libsafe阻止企图覆写栈返回地址的格式字符串漏洞 - 静态二进制分析,栈修正是否比最小值还小? 格式化字符串是静态的还是可变的?
整数安全
整数表示方法:原码、反码、补码
原码:二进制计算,符号看首位 ,首位为 0 则为 + ,首位为 1 则为 -
反码:将一个整数值除符号位之外的每一位取反,得到对应的反码表达式。
补码:正数与原码相同 ,负数在其反码的基础上,末位加1,补码表达式对 0 只用 +0 一种表达
带符号和无符号整数
带符号整型用来表示正值和负值,每一种带符号类型都有对应的无符号类型
整数取值范围
带符号数整数的取值范围 $[-2^{n-1} , 2^{n-1}-1]$
无符号数的取值范围:$[0,2^n -1]$
整数转换、整形提升、隐式转换
整数转换:类型转换既可能作为转型( cast)操作的 结果显式发生 ,也可能因为某个操作的需要而隐式发生。
整形提升:在比int小的整型进行操作时,它们会被提升。 主要是为了防止运算过程中中间结果发生溢出而导致 算术错误
隐式转换:隐式转换是C语言可以对混合数据类型执行操作能力的结果。
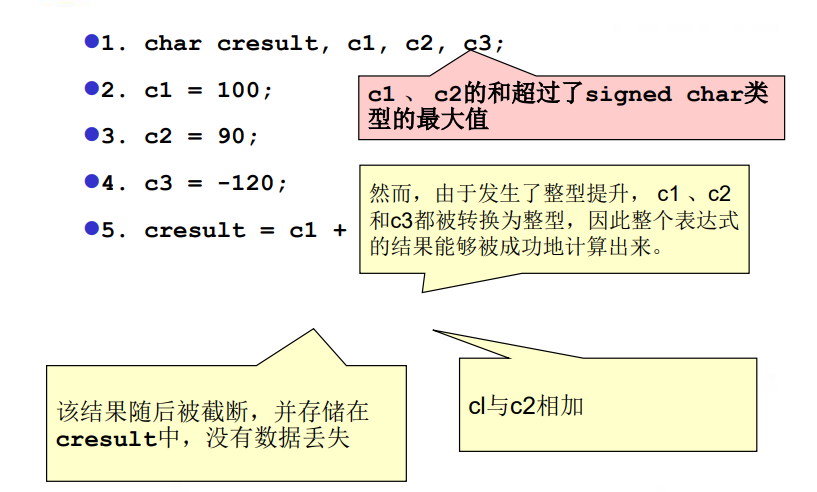
整数转换规则
无符号整数转换:
- 由小到大,进行零扩展即可
- 由大到小,较大的值将会被戳断 ,低位数据被保留
- 无符号转换成带符号:位模式(即所有的位数据)将会被保留,因此没有 数据会因此丢失 ,最高位数据变成了符号位
- 如果该符号位被置位,该值的符号和大小都会发生改变
带符号整数转换
- 非负整数转换为相同大小或更大的无符号整数:值不会发生变化 ,带符号整数需作符号扩展
- 带符号整数被转换为较短的带符号整数的时候,则 是通过截断高位完成
- 当带符号整数转换到无符号整数 其位模式被保留,故不会有数据的丢失 ,高位失去了符号位的功能
- 如果其值是负数的话,得到的无符号结果将 被求值为一个非常大的带符号整数
整数溢出类别及原理:整数溢出、截断错误、符号错误
溢出:当一个整数被增加超过其最大值或被减小小于其最小值时即会 发生整数溢出
- 带符号溢出发生于对符号 位执行进位时
- 无符号溢出则发生于当底层表 示不再能够表示-个值时。
截断:原值的低位被保留下来而高位则被丢弃。
- 将一个较大整型的数转换到较小的整型
- 该数的原值超出较小类型的表示范围
符号错误:
- 从无符号整型转换到带符号整型
- 相同大小,位模式不变,最高位变为符号位
- 更大 -> 进行符号拓展,再执行转换
- 更小 -> 保留低位
- 如果无符号整数最高位 没被设置,值不变,被设置,变成负值
动态内存安全
动态内存管理函数
calloc() malloc() realloc() free() new() delete()
内存分配算法
- 连续匹配方法:查询匹配的第一个空闲区域
- 最先匹配,从内存开始位置寻找第一个空闲区域
- 最佳匹配,有m个字节的区域被选中,其中 m 是(其中一个)可用的最小的 等于或大于 n 个字节的连续存储块
- 伙伴系统方法:伙伴系统只分配 $2^i$ 大小的块 倘若需要m大小的块,分配 $2^{[log_b m]+1}$ 大小 当块返回时,尝试和它相邻的同样大小的块合并
- 隔离:保持单独的大小一致的块的列表
常见的内存错误
- 初始化错误
- 未检查返回值
- 引用已释放的内存
- 对同一块内存释放多次
- 不正确配对的内存管理函数
- 未能区分标量和数组
- 分配函数使用不当
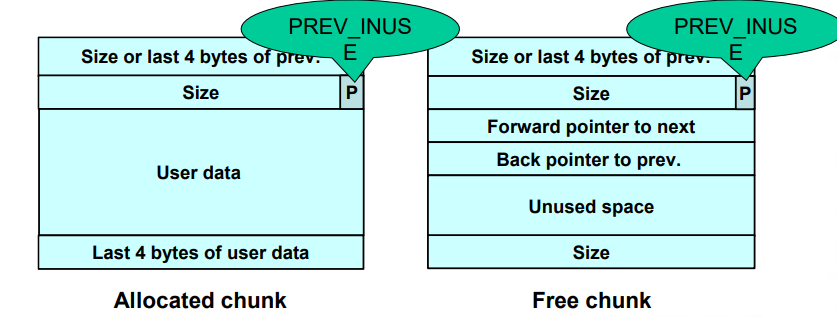
Dlmalloc 空闲块管理
空闲
- 空闲块以双链表形式组织起来,包含指向下一块的前向指针和指向上一块的后向指针,最后4字节存有该块的大小
分配
- 已分配块和空闲块都使用一个
PREV_INUSE区分 - 块大小总是偶数,
PREV_INUSE位被存储与块大小的地位中 - 在
free()时,内存块如果条件满足会被合并- 与相邻空闲块合并
- 被释放块的上一块为空闲块:与被释放的块合并
- 被释放块的下一块为空闲块:也从双链表中解开,并与被释放块合并
- 与相邻空闲块合并

- 已分配块和空闲块都使用一个
解链技术(unlink 技术)
利用缓冲区溢出来操作内存块的边界标志,欺骗unlink宏向任意位置写入4字节数据
Frontlink 技术
当一块内存被释放时,它必须被正确地链接进双链表中
- 在
dlmalloc的某些版本中,此项操作是由frontlink ()代码段 完成的 - 我们的目标
- 在攻击者指定的地址写入攻击者指定的数据
攻击者:通过往上一内存块的最后4个字节中写入 指令实现
- 指定一个内存块地址而不是
shellcode地址 - 在这个内存块的起始4个字节中放入可执行代码
RTL堆基本概念
RTL – Run Time Library
- 使用虚拟内存API
- 实现了更高级的局部、全局和CRT内存函数
进程环境块(PEB)
- PEB 维护有每一个进程的全局变量
- PEB被每一个进程的线程环境块(TEB)所引用,TEB被fs寄存器引用
- PEB给出的信息
- 堆的最大数量
- 堆的实际数量
- 默认堆的位置
- 一个指向包含所有堆位置的数组的指针
空闲链表:
- 有128个双向链表的数组 位于堆起始位置
- 这个链表被
RtlHeap用来跟踪空闲内存块
Freelist[]
- 是一个LIST_ENTRY结构的数组
- 每一个LIST_ENTRY表示一个双链表的头部
- 由一个前向链接( flink )和一个后向链接( blink )组 成
页中未作为第一个内存块的一部分而分配出 去的内存,以及那些没有被用作堆控制结构 的内存,就被加入空闲列表
对于较小的分配(指的是小于1472字节), 大于1024的被加入到Freelist[0]中
假设空间足够的话, 后续的分配都从这个空 闲块中进行
后备缓存链表:
- 在堆分配时创建
- 用于加速对小块内存( < 1016 字节)的分配操作
- 后备缓存链表已开始被初始化为空链表,后随着内存被释放而增长
- 后备缓存链表会先于空闲链表被检查
边界标志:
- 调用
HeapAlloc()或malloc()所返回的 - 这个结构位于
HeapAlloc()所返回的地址之前,偏移量为8个字节 - 包含
- 自身大小
- 前一块大小
- busy 标志位
- 传统部分
当块被释放时
- 边界标志仍然存在
- 空闲内存包含下一块和上一块地址
- busy 标志位被清空



